| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- NLP
- 전처리
- 우울증
- 인공지능
- 대학원
- 수기
- 석사
- 품사태깅
- Classification Task
- CUDA
- naver movie review
- sentiment analysis
- pytorch
- word embedding
- 자연어처리
- Word2Vec
- Today
- Total
목록전체 글 (144)
슬기로운 연구생활
* 문제 상황 import torch는 문제가 없이 잘 되었는데... import torchvision에서 에러가 터졌다. 지정된 모듈을 찾을 수 없다는 에러가 터졌다. 이게 어디서 자주 본 에러여서 기억을 더음어 보니... tensorflow gpu 할 때 본 에러였다. * 해결 방법 1. 파일 설치해보기 Intel-openmp visual studio 2017 재배포파일 Intel-openmp는 anaconda 환경에 설치하면 된다. 이 방법으로도 해결이 되지 않으면 2번 방법을 적용해보자. 2. torchvision 버전 낮춰보기 위에 방법으로 해결되지 않는다면 torchvision 버전을 0.4버전에서 0.2버전으로 낮추보자. 나는 이렇게 해서 해결했다. 내 cuda 버전과 torchvision ..
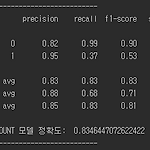 4-1. TF-IDF + NB
4-1. TF-IDF + NB
[0] 서론 - 이전에는 Bag of Words를 사용해서 Text를 Vector로 변환했었다. 이번에는 TF-IDF를 사용해서 Text를 Vector로 변환했다. - TF-IDF를 사용하면 단어의 가중치를 부여해 줄 수 있다. 하지만 NB는 단어의 가중치를 사용하지 않고 단어의 빈도수를 사용하기 때문에 BoW를 사용하든 TF-IDF를 사용하든 결과는 같을 것이라 생각했다. ( 내 생각이 틀렸다. ) - 코드는 아래 github에 공개하였다. https://github.com/vhrehfdl/Blog/blob/master/movie_review_classification/model/TF-IDF%2BNB.py vhrehfdl/Blog_code Contribute to vhrehfdl/Blog_cod..
 [Tensorflow] Google Colab 사용법 정리
[Tensorflow] Google Colab 사용법 정리
[1] Colab에 접속한다. https://colab.research.google.com/notebooks/welcome.ipynb Google Colaboratory colab.research.google.com [2] 새로운 python3.ipynb 파일을 만든 후 google drive mount를 한다. from google.colab import drive drive.mount('/content/gdrive') from google.colab import drive drive.mount('/content/gdrive') 해당 코드를 실행하면 enter authorization code를 입력하라고 창이 뜬다. [3] authorization code 받는 주소 https://co..
1. pip 툴을 사용해 pytube를 install 한다. 2. code를 돌려 youtube 영상을 다운 받는다. # -*- coding: utf-8 -*- import os import subprocess import pytube yt = pytube.YouTube("https://www.youtube.com/watch?v=ZMpQgvmw3kk") #다운받을 동영상 URL 지정 vids= yt.streams.all() #영상 형식 리스트 확인 for i in range(len(vids)): print(i,'. ',vids[i]) vnum = int(input("다운 받을 화질은? ")) parent_dir = "/home/lee" #저장 경로 지정(Windows or mac) vids[vnum]..
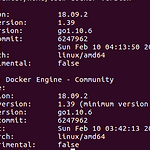 [Docker] 설치하기
[Docker] 설치하기
* Docker 설치 curl -fsSL https://get.docker.com/ | sudo sh * 설치 확인 docker version 설치가 완료되면 ( 그림1 )과 같이 결과가 나온다. * docker 명령어 모음 1) Image 파일 설치 : docker run ubuntu:16.04 2) docker run : docker run -it ubuntu:16.04 3) docker exec : 실행중인 컨테이너에 접속할 때 사용 docker exec -it mysql bash 4) docker image 확인 docker images 5) docker container 확인 docker ps -a 6) docker image 제거 docker rm..
* 설치 과정 curl https://sdk.cloud.google.com | bash exec -l $SHELL gcloud init * 새로운 버킷 생성 명령어 gsutil mb -l us-east1 gs://my-awesome-bucket/ * 파일 업로드 gsutil cp Desktop/kitten.png gs://my-awesome-bucket gsutil cp /home/lee/video/chul9hyung/5Hj3sW2OroU.wav gs://my-youtube-bucket * 버킷에 파일 조회 gsutil ls gs://my-awesome-bucket
 [ DB ] PostgreSQL 백업 복원
[ DB ] PostgreSQL 백업 복원
- PostgreSQL은 DB 특성상 console 작업이 너무 불편해 PgAdmin을 연동해야 한다. * PgAdmin 연동 - PostgreSQL 외부접속을 허용한다. 1. listen_addresses 변경 /etc/postgrsql/9.5/main/postgresql.conf 에 들어간다. 저 부분을 변경해준다. 2. host 값 추가 /etc/postgresql/9.5/main/pg_hba.conf 에 들어가 가장 마지막 부분에 한 줄 입력해준다. 3. DB 재시작 * 백업 Backup을 눌러준다. * 복구 Restore을 클릭해준다. * 참고 URL http://printhelloworld.tistory.com/143 ..
* 백업 1) DB별로 백업 mysqldump -u root -p DB명 > 파일명.sql 2) 전체 백업 mysqldump -u root -p –all-databases > 파일명.sql 3) 캐릭터셋 옵션을 이용하여 백업 mysqldump -u root -p –default-character-set=euckr DB명 > 파일명.sql 4) 특정 테이블만 덤프 mysqldump -u root -p DB명 테이블명 > 파일명.sql mysqldump -u root -p -B DB명 –tables 테이블명1 테이블명2 테이블명3 > 파일명.sql 5) 테이블 구조만 백업 mysqldump -u root -p –no-data DB명 > 파일명.sql 6) XML 파일로 백..