| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 품사태깅
- CUDA
- word embedding
- Classification Task
- 석사
- pytorch
- 수기
- naver movie review
- 인공지능
- 자연어처리
- 우울증
- 전처리
- Word2Vec
- NLP
- sentiment analysis
- 대학원
- Today
- Total
목록프로젝트 : 영화리뷰 분류 (8)
슬기로운 연구생활
 4-1. TF-IDF + NB
4-1. TF-IDF + NB
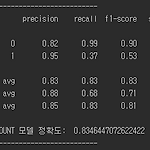
[0] 서론 - 이전에는 Bag of Words를 사용해서 Text를 Vector로 변환했었다. 이번에는 TF-IDF를 사용해서 Text를 Vector로 변환했다. - TF-IDF를 사용하면 단어의 가중치를 부여해 줄 수 있다. 하지만 NB는 단어의 가중치를 사용하지 않고 단어의 빈도수를 사용하기 때문에 BoW를 사용하든 TF-IDF를 사용하든 결과는 같을 것이라 생각했다. ( 내 생각이 틀렸다. ) - 코드는 아래 github에 공개하였다. https://github.com/vhrehfdl/Blog/blob/master/movie_review_classification/model/TF-IDF%2BNB.py vhrehfdl/Blog_code Contribute to vhrehfdl/Blog_cod..
 3-5. BoW + XGBoosting
3-5. BoW + XGBoosting
[0] 서론 - XGBoosting은 여러 Kaggle 대회에서 많이 사용하는 알고리즘이다. 성능이 좋다고 알려져있어서 사용하기 전에도 기대를 했었다. 하지만 막상 돌려보니 월등히 뛰어나지는 않았다. [1] 실험 - sklearn의 xgboost.XGBClassifier()를 사용하였다. [1-1] DataSet - Train Data ( train.csv ) 긍정 리뷰 : 93,042 / 부정 리뷰 : 275,270 - Test Data ( validation.csv ) 긍정 리뷰 : 10,338 / 부정 리뷰 : 30,586 - 평점이 1점 ~ 3점인 영화리뷰를 부정 리뷰로 분류했고 10점인 리뷰를 긍정 리뷰로 분류했다. [1-2] Text To Vector - Bag o..
 3-4. BoW + Random Forest Classifier
3-4. BoW + Random Forest Classifier
[0] 서론 - RandomForest는 사실 아무 생각 없이 사용했었다. Decision Tree 형태를 가진다는 것만 알고 있었지 이번에 적용하면서 대략적은 흐름을 알게되었다. - RandomForet도 SVM과 마찬가지로 60만개의 학습데이터를 사용하면 시간이 오래 걸리기 때문에 2만개의 학습데이터를 사용해 model을 만들었다. [1] 실험 sklearn의 ensemble.RandomForestClassifier()를 사용하였다. [1-1] DataSet - Train Data ( train_small.csv ) 긍정 리뷰 : 10,000 / 부정 리뷰 : 10,000 - Test Data ( validation.csv ) 긍정 리뷰 : 10,338 / 부정 리뷰 : 30,586..
 3-3. BoW + SVM
3-3. BoW + SVM
[0] 서론 - 처음에 SVM 분류 모델을 만들 때, 약 30만개의 학습데이터( 단어수 60만개 )를 사용해 만들려했다. 하지만 모델을 만드는 시간이 너무 오래 걸려 끝을 볼 수 없었다. 그래서 단어수를 500개로 줄여 진행했었다. 하지만 단어수를 줄여도 시간이 너무 오래 걸려서 학습데이터 수를 2만개로 줄여 진행했다. SVM을 사용할 때는 학습 데이터가 너무 많거나 단어의 수가 너무 많으면 아예 생성이 안 될만큼 시간이 오래 걸릴 수 있다. - 전체 코드와 데이터는 아래 github에 있다. /data/data_small.py로 작은 데이터 셋을 만들어 SVM 모델을 만들었다. https://github.com/vhrehfdl/Blog/blob/master/movie_review_classi..
 3-2. BoW + NB + Komoran
3-2. BoW + NB + Komoran
[1] 서론 - Komoran을 사용하여 데이터 전처리를 적용한 후 Naive Bayes 학습 모델을 만든다. - 전체 코드와 데이터는 아래의 github에 올려두었다. https://github.com/vhrehfdl/Blog/blob/master/movie_review_classification/model/BoW%2BNB%2BKomoran.py - /data/data_preprocessing.py 에서 Konlpy의 Komoran을 사용해 전처리를 진행했다. - /model/BoW+NB+Komoran.py 에서 학습을 진행했다. [2] 실험1 - 전처리 단계에 stemming 적용 ex) "내시간 돌려내" 라는 문장이 있으면 "내 시간 돌리 어 내 어"와 같이 원형복원이 된다. 원형복원..
 3-1. BoW + NB
3-1. BoW + NB
[1] Data Set ( Train Data ) - 긍정 리뷰 : 93,042 / 부정 리뷰 : 275,270 ( Test Data ) - 긍정 리뷰 : 10,338 / 부정 리뷰 : 30,586 평점이 1점 ~ 3점인 영화리뷰를 부정 리뷰로 분류했고 10점인 리뷰를 긍정 리뷰로 라벨링했다. [2] Text To Vector 텍스트 데이터를 NB에 그대로 넣을 수 없으니 Vector로 변환하는 과정을 거쳤다. BoW을 사용해 Text를 Vector로 변형하였다. Vector의 차원수 : 602,884 ( 형태소 분석기를 사용해 전처리를 하면 차원수가 감소할까? 조사와 같은 불필요한 품사들을 제외하고 명사, 형용사, 동사 등 중요한 품사만 사용하면 차원수를 줄일 수 있을 것 같다. 실험해봐..
 2. 데이터 가공
2. 데이터 가공
[1] 기본 데이터 다운 - https://github.com/e9t/nsmc 해당 github에서 raw 폴더 데이터를 다운 받는다. (그림1)을 보면 raw 폴더 내부에는 수천개의 json 파일이 있고 json 파일의 (그림2)와 같은 형태로 구성되어 있다. [2] 데이터 가공 여러개의 json 파일을 하나의 CSV 파일로 합친다. 그리고 해당 CSV 파일을 학습 데이터로 사용한다. data_sum.py를 사용해 하나의 CSV 파일로 만들었다. import json import csv import os ''' [1] 목적 raw 폴더에 존재하는 데이터를 하나의 파일로 합쳐준다. json 파일로 분할되어 있는 데이터를 필요한 부분만 가져와 하나의 CSV 파일로 합친다. 그리고 해당 CSV 파일을 학습 ..
[ 기간 ] 2019.01 ~ 2019.03 [ 목표 ] 1. 네이버 영화 대글의 긍정, 부정을 분류하는 모델을 만든다. 2. 95% 이상의 정확도를 갖는 모델을 만든다. 3. 굉장히 다양한 모델을 사용해보자. 4. 문서화를 잘해서 다른 사람들과 공유하자. [ 데이터 ] https://github.com/e9t/nsmc e9t/nsmc Naver sentiment movie corpus. Contribute to e9t/nsmc development by creating an account on GitHub. github.com