| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 품사태깅
- 전처리
- Classification Task
- 수기
- naver movie review
- sentiment analysis
- 인공지능
- Word2Vec
- 자연어처리
- NLP
- 우울증
- 석사
- pytorch
- word embedding
- 대학원
- CUDA
- Today
- Total
슬기로운 연구생활
Classification - [12] GPT 본문
이전 글
[6] One-Hot Encoding, Bag Of Word
들어가며
최근의 GPT-3가 놀라운 성능을 보여주며 GPT에 대한 관심이 높아졌습니다.
GPT-3는 굉장히 뛰어난 문장 생성 결과를 보여주고 있습니다.
GPT는 OpenAI에서 만든 모델로 Transformer라는 모델의 Decoder 부분만 사용한 LM입니다. ( 이후에 살펴볼 BERT도 Transformer 기반입니다. )
Transformer에 대한 설명은 추후, "Attention is all you need"라는 논문을 리뷰하면서 깊게 살펴보겠습니다.
이번 글에서는 Transformer의 Decoder 부분을 어떻게 활용했는지 GPT만의 특징들에 대해 알아보겠습니다.
GPT
GPT-1, GPT-2, GPT-3의 모델 구조는 모두 동일합니다.
버전마다 다른 것은 학습 데이터의 양과 Transformer Decoder 블럭의 개수입니다. ( 입력층에서 사용하는 토큰화 방법 등이 달라지기는 하지만 전체적인 구조는 거의 비슷합니다. )
아래 그림의 Trm은 Transformer Decoder를 의미합니다.
ELMo는 Forward 방향과 Backward 방향을 각각 학습한다면 GPT는 Forward 방향으로 학습을 진행합니다.
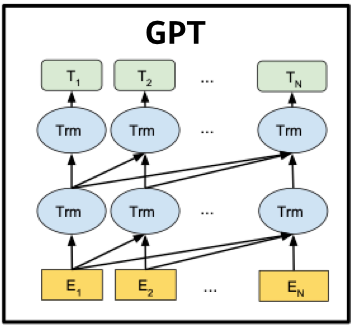
GPT의 Seq2Seq 학습 방법과 유사하며 과정은 다음과 같습니다.
첫째, 문장이 BPE(Byte Pair Encoding)을 거쳐 Token으로 분리됩니다.
둘째, 토큰으로 분리된 문장은 Token Embedding Matrix를 거쳐 임베딩으로 변환된 후, Transformer Decoder Block에 입력됩니다.
셋째, Transformer Decoder Block을 거친 후 Softmax를 거쳐 가장 확률이 높은 단어를 선택합니다.
Byte Pair Encoding
BPE는 단어를 Character 단위로 나누어 Subword를 생성하는 방법입니다.
Character 단위로 나누기 때문에 이전의 Fasttext에서 설명했던 Out of Vocabulary 문제가 덜 생깁니다.
단어를 형태소 분석기로 나누어 사전에 등록하게 되면 생각보다 단어의 수가 부족할 수 있기 때문에, Character 단위로 나누어 OOV 문제를 해결하는 것은 중요한 일입니다.
BPE의 구현 흐름은 다음과 같습니다.
vocab = {"low":5, "lower":2, "newest":6, "widest":3}이 있다고 가정하겠습니다.
첫째, vocab에 </w>를 추가합니다.
vocab = {"l o w </w>":5, "l o w e r </w>":2, "n e w e s t </w>":6, "w i d e s t </w>":3}
둘째, 반복적으로 빈도수가 많은 단어를 순서대로 추출합니다.
[Step 1]
l o w </w> → lo ow w</w>
l o w e r</w> → lo ow we er r</w>
n e w e s t </w> → ne ew we es st t</w>
w i d e s t </w> → wi id de es st t</w>
"es". "st" → 9번
"we:" → 8번
"lo", "ow" → 7번
"e"과 "s"가 동시에 포함된 단어 newest의 수는 6이고 widest의 수는 3이기 때문에 더해서 9가 됩니다.
마찬가지로 "s"와 "t"가 동시에 포함된 단어의 수는 6과 3을 더해 9가 됩니다.
[Step 2]
l o w </w> → lo ow w</w>
l o w e r </w> → lo ow we er r</w>
n e w [es] t</w> → ne ew wes est t</w>
w i d [es] t</w> → wi id des est t</w>
"est" → 9번
"lo", "ow" → 7번
"ne", "ew", "wes", "t</w>" → 6번
"es"와 "t"가 동시에 들어있는 단어 "newest"가 6번 등장했고 "widest"가 3번 등장해 9번이 됩니다.
셋째, 이런식으로 지정된 회수까지 반복한 후 최종적으로 Merge한 결과 값을 도출합니다.
[low</w>] → 5번
[low] e r </w> → 2번
[newest</w>] → 6번
[wi] d [est</w>] → 3번
위의 리스트를 분리하면 아래와 같이 dictionary가 생성됩니다.
{'low</w>': 5, 'low': 2, 'e': 2, 'r': 2, '</w>': 2, 'newest</w>': 6, 'wi': 3, 'd': 3, 'est</w>': 3}
BPE 관련 코드는 다음과 같습니다.
def get_stats(dictionary):
# 유니그램의 pair들의 빈도수를 카운트
pairs = collections.defaultdict(int)
for word, freq in dictionary.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
print('현재 pair들의 빈도수 :', dict(pairs))
return pairs
def merge_dictionary(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
bpe_codes = {}
bpe_codes_reverse = {}
for i in range(num_merges):
display(Markdown("### Iteration {}".format(i + 1)))
pairs = get_stats(dictionary)
best = max(pairs, key=pairs.get)
dictionary = merge_dictionary(best, dictionary)
bpe_codes[best] = i
bpe_codes_reverse[best[0] + best[1]] = best
print("new merge: {}".format(best))
print("dictionary: {}".format(dictionary))
Transformer Decoder
BPE를 사용해 입력 문장을 입력층에 넣으면 사전이 생성되고 문장은 토큰화 됩니다.
그리고 Token Embedding과 Positional Encoding 값을 합쳐 Input Embedding으로 Transformer Decoder에 입력합니다.

Transformer Decoder에 토큰을 입력하면 여러개의 Decoder를 거쳐 최종적으로 Output Vector가 생성됩니다.
해당 Output Vector에 Token Embedding을 적용해 해당 값 중 가장 단어가 높은 것이 다음 단어가 됩니다.
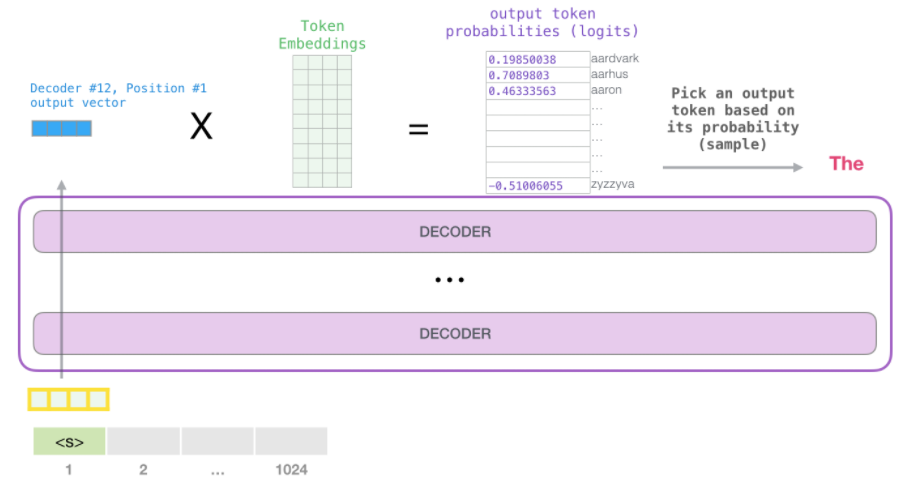
학습에서는 <s>라는 단어를 입력했을 때 출력되는 아웃풋 확률값과 실제 정답값을 Cross Entropy하여 Loss를 줄여나가는 방법으로 학습을 진행합니다.
추론할 때는 <s>라는 단어를 입력했을 때 나오는 출력값을 다음 스탭 입력값으로 넣어 반복적으로 단어가 출력되게 합니다.
마무리
이번 글에서는 GPT에 대해 알아보았습니다.
GPT는 Seq2Seq 학습 흐름에 내부 알고리즘은 Transformer에 Decoder를 사용해 학습이 진행되었습니다.
해당 글에서는 GPT의 전체 흐름만 간략하게 소개했고 추후에 Attention is all you need를 통해 Transformerd의 Decoder 구조를 살펴봐주시면 감사하겠습니다.
'슬기로운 NLP 생활' 카테고리의 다른 글
| Classification - [14] Model (0) | 2020.12.09 |
|---|---|
| Classification - [13] BERT (0) | 2020.10.07 |
| Classification - [11] ELMo (0) | 2020.09.24 |
| Classification - [10] GloVe (0) | 2020.09.13 |
| Classification - [9] Fasttext (0) | 2020.09.02 |



