| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 석사
- 우울증
- naver movie review
- Word2Vec
- 품사태깅
- Classification Task
- NLP
- word embedding
- pytorch
- sentiment analysis
- 자연어처리
- 수기
- 대학원
- 전처리
- CUDA
- 인공지능
- Today
- Total
슬기로운 연구생활
Classification - [8] Word2vec 본문
이전 글
[6] One-Hot Encoding, Bag Of Word
들어가며
앞서 소개했던 Bag of Words와 TF-IDF는 Count Based Language Model에 속합니다.
왜나하면 단어를 vector로 표현할 때 단어의 빈도수를 특성으로 표현하기 때문입니다.
Count Based Language Model의 단점은 Sparse Vector이기 때문에 하나의 단어를 표현하는데 불필요한 공간이 소모된다는 것과 단어간의 의미적 유사성을 알 수 없다는 것입니다.
이번글에서 소개할 Language Model은 위의 문제를 해결한 Neural Network Based Language Model입니다.
NNLM은 대표적으로 Word2vec, FastText, Glove와 같은 방법들이 존재합니다.
오늘은 그 중에서 Word2vec을 공부해보겠습니다.
Count Based Word Representation 문제점
- Problem 1 : 하나의 단어를 표현하는데 큰 벡터가 필요합니다.
One-Hot Encoding에서는 하나의 Columns이 Vocabulary에 등록된 단어를 의미합니다.
강아지 : [ 1 0 0 ]
멍멍이 : [ 0 1 0 ]
고양이 : [ 0 0 1 ]
만약 사전에 30,000개의 단어가 들어있다면 하나의 단어를 표현하기 위해서는 30,000 차원이 필요합니다.
( Count Based LM은 듬성 듬성한 Sparse Vector의 모습을 가지게 됩니다. )
큰 차원의 벡터는 메모리 등의 문제 때문에 계산복잡성이 크게 늘어나게 됩니다.
그리고 실제 위의 벡터에서 필요한 값은 1이 들어간 하나의 요소 뿐이고 나머지는 불필요한 0이 포함되어 있습니다
- Problem2 : 단어사이에 관련성을 파악할 수 없습니다.
강아지 : [ 1 0 0 ]
멍멍이 : [ 0 1 0 ]
예를 들어 "강아지"와 멍멍이"가 유사하다는 것을 Count Based LM에서는 알 수 없었습니다.
위의 Vector를 내적하면 0이 됩니다.
길이가 1인 두 벡터의 내적은 두 벡터 사이의 각도가 되므로 두 벡터가 직교한다는 의미가 됩니다.
이를 확장해서 생각하면 One-Hot Encoding은 서로 독립한다는 것을 알 수 있습니다.
즉, 모든 단어가 서로 관련이 있지 않다는 것을 의미합니다.
Distributed Representation
위의 문제들을 해결하기 위해 Distributed Representation(분산 표상)을 사용합니다.
( 그림1 )을 보면 총 9개의 도형이 있습니다.
초록색 해 / 초록색 달 / 초록색 구름
파란색 해 / 파란색 달 / 파란색 구름
주황색 해 / 주황색 달 / 주황색 구름
만약 파란색 해를 One hot encoding으로 표현한다면 [ 0 0 0 1 0 0 0 0 0 ] 이 될 것입니다.

위의 9차원 벡터는 2차원 벡터로도 표현 가능합니다.
각 도형의 속성인 colors와 shapes를 조합하여 9개의 도형을 표현할 수 있기 때문입니다.
분산표상은 데이터의 차원수를 줄여주기도 하지만 개체간 유사성을 비교할 수도 있게 만들어줍니다.
의미가 유사한 단어는 벡터 공간에서 가깝게, 반대의 경우에는 멀게 배치하는 것이 분산표상의 목표입니다.
Word2vec에서 단어 Vector는 "강아지" = [ 0.2, 1.8, 2.8 ... , -7.2 ]와 같이 표현됩니다.
이전의 Count-Based LM에서 Vector의 길이는 Vocabulary에 등록된 단어를 의미했습니다.
그렇다면 Word2vec에서 Vector의 Column은 위에서 언급한 colors, shapes와 같은 특성을 의미하는 것일까요?
그것은 아닙니다.
Word2vec의 각 Column은 colors와 shapes의 특성이 혼합된 것을 의미합니다.
즉 "강아지"라는 단어 vector에서 0.2 가 동물, 1.8이 종류를 나타내는 것이 아닙니다.
여러 특성이 섞여서 수치로 표현 되는 것입니다.
"강아지" = [ 0.2, 1.8, 2.8 ... , -7.2 ]와 같이 vector의 값이 dense(빽빽하게) 있기 때문에 Dense Vector라고도 합니다.
Word2vec
위에서 설명한 분산 표상을 가지는 Vector를 만들기 위해서 Shallow Neural Network 모델에서 학습을 진행합니다.

- Input Layer에는 One-Hot Encoding의 값이 들어갑니다.
강아지 = [ 1 0 0 ] 의 값이 들어가는 것입니다.
x1 = 1 / x2 = 0 / x3 = 0
- Hidden Layer에서 Weight와 Bias의 값이 존재합니다.
초기 Weight&Bias는 random하게 설정되며 back propagation을 할 때 서로 가까운 거리를 가지도록 Weight가 업데이트됩니다.
Hidden Layer의 노드 개수는 사용자가 정의하며 Word Embedding에서 embedding dimention을 의미합니다.
- Output Layer에서는 Input Layer와 노드의 개수가 같습니다.
Input Layer와 Output Layer 노드 개수는 One-hot Encoding의 dictionary 개수와 같습니다.
출력값은 [ 0 1 0 ] 을 가지게 됩니다.
y1 = 0 / y2 = 1 / y3 = 0
멍멍이 = [ 0 1 0 ]
NNLM의 학습은 다음 단어가 무엇인지를 예측하는 방법으로 진행됩니다.
"The fat cat sat on the mat" 이라는 문장이 있습니다.
Input에는 The = [ 1 0 0 0 0 0 0 ] 이 들어가고 hidden layer를 거쳐서 predict 한 값이 [ 0 1 0 0 0 0 0 ]이 되도록 학습을 진행하다는 것입니다.
이렇게 학습을 진행하면 단어간의 의미적인 관계가 담겨있는 weight vector가 생성된다는 것이 NNLM의 기본개념입니다.
NNLM의 학습방식은 CBOW와 Skip-gram이 존재합니다.
CBOW
CBOW는 주변 단어를 사용해 중간 단어를 예측하는 방법입니다.

- (그림3)을 보면 중심 단어를 기준으로 앞뒤 2개의 단어를 학습데이터로 사용을 합니다. ( 앞뒤 N개의 단어를 설정하는 파라미터가 Word2vec에서는 window size입니다. )
주변 단어를 Input에 넣고 Hidden Layer를 거쳐서 Output Layer에서 나온 값이 중심 단어가 되도록 학습시키는 것입니다.

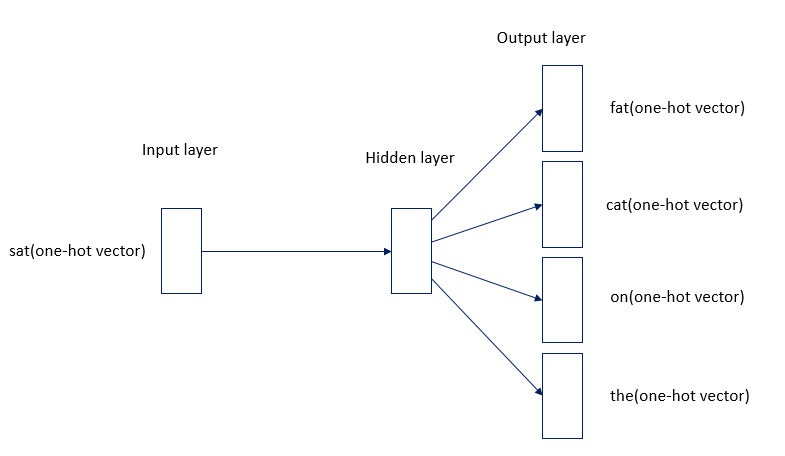
- (그림4)는 (그림3)을 이해하기 쉽게 도식화한 이미지입니다.
"sat"이라는 중심단어를 예측하기 위해 "fat", "cat", "on", "the"와 같은 주변 단어를 입력합니다.

- (그림5)를 보면 알 수 있듯이 4개의 벡터 값의 평균을 구하여 해당 Vector 값을 Word Vector로 사용합니다.
Skip-Gram
Skip-gram은 CBOW와 반대로 중심단어를 사용해 주변단어를 예측하는 방법입니다.
보통 CBOW보다 Skip-gram을 많이 사용한다고 하는데 이유는 다음과 같습니다.
CBOW에서는 주변단어를 4개를 사용해 predict를 하고 한 번만 역전파를 진행합니다.
하지만 skip-gram에서는 중심단어 1개를 사용해 predict를 하고 네 번 역전파를 진행합니다.
즉, skip-gram이 역전파하는 회수가 CBOW보다 더 많기 때문에 학습이 잘 된다고 합니다.
Dense Vector
Word2vec을 이용해 단어의 vector를 구한다는 것은 NNLM의 신경망에서 학습된 가중치 벡터를 가져오는 것입니다.

- ( 그림7 ) 과 같이 좌측 행렬은 단어를 의미하는 행렬이고 우측 행렬은 Shallow Neural Network의 weight vector입니다.
"강아지"라는 단어는 [ 10 12 19 ] 라는 벡터로 표현되는 것입니다.
이것은 weight vector의 행이 각 단어의 벡터를 의미한다고 볼 수 있습니다.
왜냐하면 [ 0 0 0 1 0 ]에서 보는 것처럼 0과 곱해지면서 1이 포함된 weight vector의 행만 출력이 되기 때문입니다.
그렇다면 weight vector는 어디서 가져올까요?
wiki-docs 와 같은 데이터를 Pre-trained한 Weight vector 값을 가져올 수 있습니다.
아니면 자신의 목적에 맞게 학습을 시켜 Weight vector를 생성하고 그 vector 값을 가져와 사용할 수 있습니다.
wiki-docs에서 사전에 학습한 weight vector 값을 가져온다고 가정해보겠습니다.
wiki-docs가 많은 단어를 가지고 있기는 하지만 내가 사용하는 데이터의 단어를 가지고 있지 않은 경우도 있을 것입니다.
그런 경우에는 해당 단어의 vector 값을 0으로 설정하거나 random 하게 설정합니다.
설계하기 나름입니다.
특징
Word2vec은 하나의 단어를 표현하는데 큰 Vector 값이 필요하지 않습니다.
기존의 Count Based LM에서는 사전의 단어 개수가 차원수 였다면, NNLM에서는 사용자가 embedding_dim을 몇으로 정의하는가에 따라 단어의 차원수가 정해집니다.
즉, 한 단어를 표현하는 Vector 값이 300개가 될 수도 있고 50개 될 수도 있습니다.
Word2vec은 의미적으로 유사한 단어를 파악할 수 있습니다.
각 단어를 표현한 Vector 값에 Cosine Similarity를 적용하면 의미적으로 유사한 단어가 출력됩니다.
이는 한 문장에 동시에 등장하는 단어는 서로 연관성이 있다는 가정하에 학습을 진행하기 때문에 각 단어의 Vector값은 주위 단어와의 관계를 반영해 표현 됩니다.
그래서 "한국"이란 단어를 넣었을 때 "일본"과 "미국" 등 국가와 관련된 단어가 출력 되는 것입니다.
Word2vec 구현
Word2vec을 Gensim 라이브러리를 사용해 직접 구현하였습니다.
한겨레 신문의 정치 기사 1000개를 수집하였고 구현 과정은 3가지로 구성되었습니다
전체 코드는 github에 공개되어 있습니다.
vhrehfdl/Blog_code
Contribute to vhrehfdl/Blog_code development by creating an account on GitHub.
github.com
첫째, 여러 단락으로 구성되어 있는 한겨레 기사를 문장 단위로 잘라줍니다.
문장 by 문장으로 잘라서 정리를 한 후, corpus.txt라는 파일을 만들어줍니다.
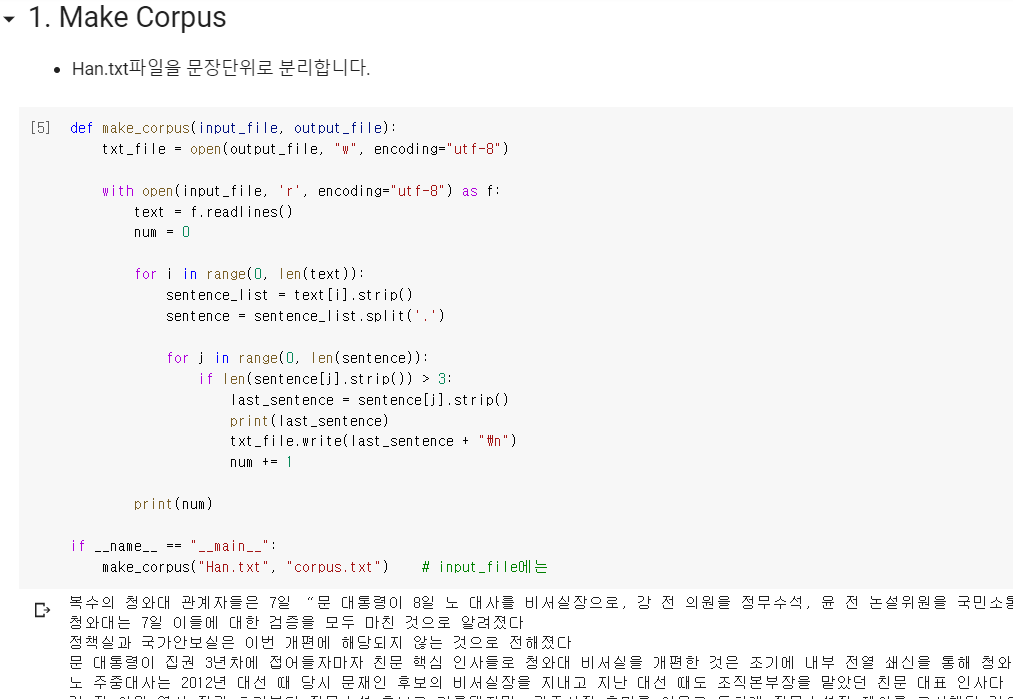
둘째, 문장을 Token으로 분리해줍니다.
Konlpy의 Komoran 모듈을 사용해 문장을 Token으로 변환시켜주었습니다.
Corpus.txt라는 문장이 담겨있는 파일을 Token으로 변환시켜 corpus_token.txt라는 파일을 만듭니다.

셋째, coupust_token 데이터를 사용해 학습을 진행합니다.
서울이란 단어의 Vector는 아래 결과 값과 같습니다.
그리고 서울과 가장 유사한 단어로 "경기도", "종로구", "창원" 과 같은 도시 지명이 출력이 됩니다.

마무리
이번 글에서는 Word Embedding에 가장 기초인 Word2vec에 대해 살펴보았습니다.
Word2vec의 개념은 매우 간단하지만 놀라운 성능을 보여주는 방법입니다.
다음 글에서는 Word2vec과 유사한 Fasttext에 대해 알아보겠습니다~!
Reference
[1] https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/
[2] https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/29/NNLM/
[3] https://wikidocs.net/22660
[5] https://lovit.github.io/nlp/2018/04/05/space_odyssey_of_word2vec/
[6] https://tensorflowkorea.gitbooks.io/tensorflow-kr/content/g3doc/tutorials/word2vec/
'슬기로운 NLP 생활' 카테고리의 다른 글
| Classification - [10] GloVe (0) | 2020.09.13 |
|---|---|
| Classification - [9] Fasttext (0) | 2020.09.02 |
| Classification - [7] TF-IDF (1) | 2020.08.23 |
| Classification - [6] One-Hot Encoding, Bag Of Word (0) | 2020.08.23 |
| Classification - [5] 형태소 분석기 (0) | 2020.08.23 |



