| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자연어처리
- pytorch
- Classification Task
- Word2Vec
- 석사
- 우울증
- 전처리
- 인공지능
- word embedding
- CUDA
- sentiment analysis
- 품사태깅
- naver movie review
- NLP
- 수기
- 대학원
- Today
- Total
슬기로운 연구생활
Classification - [11] ELMo 본문
이전 글
[6] One-Hot Encoding, Bag Of Word
들어가며
슬기로운 자연어처리[6] - [10]까지는 Word Representation에 대해 알아보았습니다.
이번 글 부터는 ELMo, GPT-1, BERT 순서대로 뛰어난 성능을 보이는 Contextualized Word Representation에 대해 알아보겠습니다.
순서는 알고리즘이 발표된 순서이며 차근 차근 살펴보도록 하겠습니다.
기존 Word Representation 방법의 문제점
1. Count Based Word Representation : BoW, TF-IDF
- 장점 : 매우 직관적이며 단어의 빈도수를 직접적으로 Vector에 표현할 수 있는 장점이 있습니다.
- 단점 : 하지만 빈도수 기반 방식은 단어 사이의 의미적 유사성을 파악하는데 한계가 존재하며 한 단어를 표현하는데 불필요한 값(0)들이 필요했습니다.
2. Fixed Word Embedding : Word2vec, Fasttext, Glove
- 장점 : 단어 사이의 의미적 유사성을 파악할 수 있고 한 단어를 표현하는데 불필요한 공간 낭비가 없습니다.
- 단점 : 하지만 Word Embedding 방법은 고정된 Vector이기 때문에 문맥에 따라 변하는 단어의 의미를 Vector에 표현할 수 없습니다.
예를 들어 "배"라는 단어를 Vector로 표현하면 [ 0.2, 1.7, 2.3 ] 으로 표현된다고 가정해보겠습니다.
"배를 먹었다", "배가 아프다" 라는 문장을 Vector로 표현할 경우 "배"라는 의미는 문장에서 다르지만 Vector는 같은 값을 가집니다.
연구자들은 주변에 있는 단어 정보를 반영해 Vector 값을 표현하는 방법을 제안했습니다.
ELMo
ELMo는 GPT-1, BERT, RoBERTa와 비교해 상대적으로 이해하기 쉬운 알고리즘 입니다. ( ELMo는 LSTM 기반이며 비교적 단순한 구조입니다. BERT 계열은 Attention 기반의 Transformer로 구성되어져 있기 때문에 비교적 어렵습니다. )
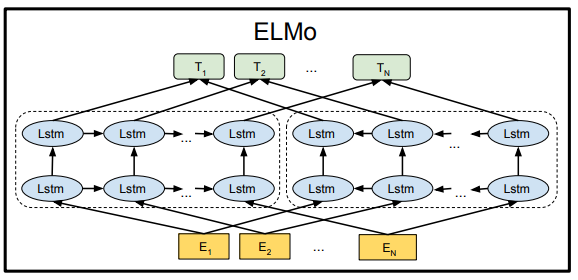
학습 방식은 위의 그림과 같이 "배를 타고 떠났다"라는 문장을 각기 다른 방향으로 학습합니다.
Forward Language Model : "배를" -> "타고" -> "떠났다"
Backward Language Model : "떠났다" -> "타고" -> "배를"
ELMo는 세개의 층으로 구성되었습니다.
1. CharCNN을 이용한 입력층
2. LSTM을 이용한 은닉층 (Forward)
3. LSTM을 이용한 은닉층 (Backward)
AllenNLP에서 구현한 코드와 옵션 파일을 통해 세개의 층을 살펴보겠습니다.
CharCNN
ELMo의 Input Layer는 CharCNN으로 구성되어 있습니다.
CharCNN은 ELMo에서 단어를 벡터로 변환하는 가장 초기 단계의 입력층입니다[1].
문장에 CharCNN이 적용되는 과정은 다음과 같습니다.
1. "I love you"라는 문장을 단어로 Split합니다.
2. "I", "love", "you"로 분리된 단어에 CharCNN을 적용해 단어의 벡터값을 생성합니다. ( 이전에 배웠던 Word2vec, Fasttext, Glove와 같이 Dense Vector가 생성되게 됩니다. )
3. "love" 단어에 CharCNN을 적용하면 각 알파벳에 대해 벡터 값이 생성됩니다.
"l" = [ 0.1 ... -2.3 ], "o" = [ -3.1 ... -0.3 ], "v" = [ 7.9 ... -3.3 ], "e" = [ 0.4 ... -1.5 ]
4. "love" 단어는 2차원 벡터값으로 형성이 되며 Convolution Mask, Max Pooling, Highway network 과정을 거쳐 1차원 벡터로 변환됩니다.
5. 위의 과정을 거치면 단어는 1차원 벡터가 되고 문장은 단어의 집합이니 2차원 벡터로 표현됩니다.

CharCNN에 대한 세부 과정을 AllenNLP의 코드와 옵션 파일을 통해 살펴보겠습니다.
AllenNLP의 Original 모델의 CharCNN 옵션 설정은 다음과 같습니다.
"char_cnn": {"activation": "relu",
"filters": [[1, 32], [2, 32], [3, 64], [4, 128], [5, 256], [6, 512], [7, 1024]],
"n_highway": 2,
"embedding": {"dim": 16},
"n_characters": 262,
"max_characters_per_token": 50}
CharCNN의 학습 방법은 다음과 같습니다.
첫째, Character Lookup Table과 초기 Character Vector를 생성합니다.
Character Lookup Table은 아래 좌측의 테이블처럼 글자들의 Embedding Vector 값을 저장해둔 테이블입니다.
Character이기 때문에 A, B, C와 같은 알파벳 단어들로 구성되어져 있으며 AllenNLP 옵션을 보면 n_characters가 262로 설정이 되어있고 embedding dimension은 16으로 설정되어 있습니다.
Lookup Table은 (262 x 16)의 2차원 행렬 입니다.
character은 알파벳 뿐만 아니라 ".", "?", "!" 같은 특수 기호들도 포함 되어 있기 때문에 262개가 되었습니다.
문자에 대응하는 유니코드 값으로 변하기 때문에, "A" - 1, "B" - 2, "<PAD>" - 262로 변합니다.
예를들어, "cat"은 3바이트이며 10진수로 바꾸면 3,1,12로 변환됩니다.

우측의 테이블은 cat이라는 단어를 vector로 변환한 파일입니다.
단어의 시작하는 부분에 <BOW>를 붙이고 단어가 끝나는 부분에 <EOW>토큰을 추가합니다.
그 후, <PAD> 값으로 공백을 채웁니다.
옵셥 파일에 max_character_per_token의 개수가 50으로 설정이 되어 있으므로 ( 50 x 16 )의 형태를 가지게 되며, 위의 5개 단어외에 45개의 단어는 <PAD> 값으로 채웁니다.
둘째, 위와 같이 벡터 값 셋팅을 마친 후에는 CNN을 적용합니다.
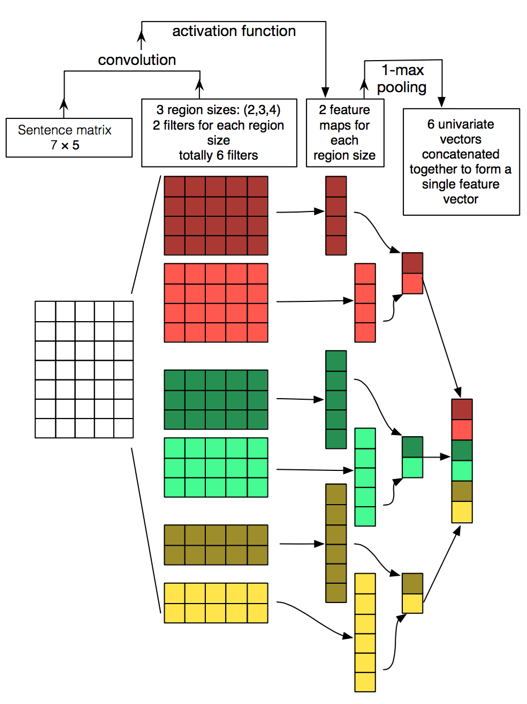
위와 같이 Word Matrix에 Convolution Mask를 적용해 Feature map을 생성합니다.
옵션 파일의 filters 변수를 보면 [1, 32], [2, 32], [3, 64], [4, 128], [5, 256], [6, 512], [7, 1024]입니다.
[Convolution mask 사이즈, filter 개수]를 의미하며 Convolution Mask의 사이즈는 (1, Embedding_dim), (2, Embedding_dim)과 같이 설정됩니다.
Mask를 씌워 Feature Map을 추출한 후, Max Pooling을 적용하면 한 단어의 Vector의 형태는 (1x2048)로 표현 됩니다. (32+32+64+128+256+512+1024=2048로 계산됩니다.)
셋째, 각 단어마다 2048 차원의 벡터가 생성이 되면 highway를 거쳐 최종 벡터가 생성됩니다.
Highway Network는 Residual Connection의 효과와 유사한 결과를 보여줍니다.

AllenNLP에서 Char CNN을 구현한 코드는 다음과 같습니다.
아래의 forward 함수의 convs=[]부터 CNN이 적용이 됩니다.
for문을 이용해 [[1, 32], [2, 32], [3, 64], [4, 128], [5, 256], [6, 512], [7, 1024]]의 Convolution Mask 사이즈와 num_filters의 개수를 설정해줍니다.

그 후, torch.max를 사용해 max_pooling을 적용합니다.
마지막으로, self._highways 코드에서 highway network가 적용됩니다.
CharCNN의 장점은 dog와 doggy의 연관성 찾아내고 OOV(Ouf Of Vocabulary)에도 견고하다는 점입니다.
이 장점은 [9] Fasttext 에서 설명했던 Fasttext와 유사한 효과를 가집니다.
LSTM
CharCNN을 거친 후에는 단어가 벡터값으로 표현됩니다.
아래의 그림처럼 각 단어의 벡터 값을 LSTM에 입력합니다.
붉은색 네모는 Forward 방향으로 학습하는 LSTM이며 파란색 네모는 Backward 방향으로 학습하는 LSTM 입니다.

사전 학습(Pre-training)때는 다음 단어를 예측하며 학습합니다.
예를들어 "The"가 들어오면 "cat"이라는 단어가 출력이 되도록 학습합니다.
사전 학습된 모델을 가져와 Inference 하는 과정을 알아보겠습니다.
LSTM 옵션 세팅은 다음과 같습니다.
"lstm": {"use_skip_connections": true,
"projection_dim": 512,
"cell_clip": 3,
"proj_clip": 3,
"dim": 4096,
"n_layers": 2}
n_layers 변수는 2이기 때문에 LSTM은 2개의 레이어로 구성되었고 LSTM 내부의 cell 개수는 4096으로 구현되었습니다.
LSTM의 weight는 3개이며 input weight는 (2048 x 4096), hidden weight는 (4096 x 4096), output weight는 (4096 x 512)가 됩니다. projection_dim이 512로 설정되어 있기 때문에 output weight가 (4096 x 512)가 됩니다.
사전 학습(Pre-training) 모델을 가져와 inference 할 때는 세개층의 출력값(CharCNN 출력값 + 1st LSTM 출력값 + 2nd LSTM 출력값)을 가져와 concatenate 합니다.
연산 과정은 아래 그림과 같습니다.

위의 과정을 AllenNLP 코드에서 확인해보면 다음과 같습니다.
첫째, inputs 값은 CharCNN을 거칩니다.
ElmoCharacterEncoder는 CharCNN을 구현한 함수이며 _token_embedder에 맵핑됩니다.

self._token_embedder(inputs)를 보면 입력값은 charCNN을 거칩니다.
둘째, self._elmo_lstm(type_representation, mask)를 거쳐 Bilm을 거칩니다.
output_tensorfs라는 변수에 결과값이 담겨있습니다.
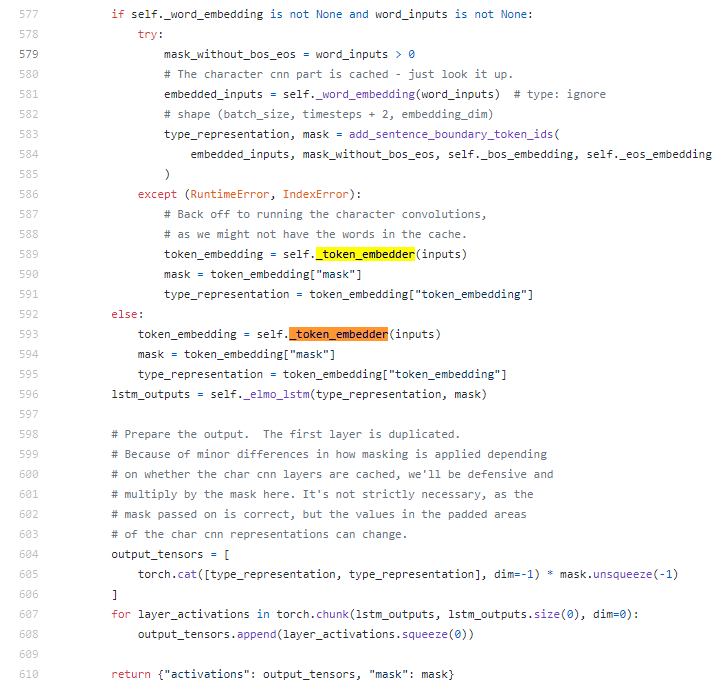
셋째, 각 lstm의 출력 값을 하나로 합쳐 연산해 elmo_representation 값을 구한다.

위의 코드는 사전 학습 과정이 아닌 inference하는 과정을 표현한 코드입니다.
그래서 forward lstm과 backward lstm 관련된 코드들이 없고 사전에 저장된 weight matrix 값을 가져와 연산하는 과정이 표현 되었습니다.
마무리
이번글에서는 LSTM 기반의 ELMo에 대해 알아보았습니다.
ELMo는 기존의 Word2vec, Fasttext, Glove와 다르게 단어의 벡터 값이 단어의 위치와 주변 단어에 따라 계속해서 변하게 됩니다.
그래서 Contextualized Word Embedding이며 이후 GPT, BERT, GPT-2, RoBERTa도 마찬가지로 계속해서 단어의 벡터값이 변하게 됩니다.
다음글에서는 Attention 기반의 Transformer로 이루어진 GPT에 대해 알아보도록 하겠습니다.
Reference
[1] Kim, Yoon, et al. "Character-aware neural language models." arXiv preprint arXiv:1508.06615 (2015).
[2] Peters, Matthew E., et al. "Deep contextualized word representations." arXiv preprint arXiv:1802.05365 (2018).
[3] www.mihaileric.com/posts/deep-contextualized-word-representations-elmo/
[5] www.quantumdl.com/entry/3%EC%A3%BC%EC%B0%A81-CharacterAware-Neural-Language-Models
[6] gyuhannkyu.github.io/methodology/2020/04/10/methodology-4.html
[7] petrlorenc.github.io/ELMO/
[9] hugrypiggykim.com/2018/06/08/elmo-deep-contextualized-word-representations/
'슬기로운 NLP 생활' 카테고리의 다른 글
| Classification - [13] BERT (0) | 2020.10.07 |
|---|---|
| Classification - [12] GPT (0) | 2020.10.07 |
| Classification - [10] GloVe (0) | 2020.09.13 |
| Classification - [9] Fasttext (0) | 2020.09.02 |
| Classification - [8] Word2vec (2) | 2020.08.24 |



